부스팅(boosting)은 앙상블 학습(ensemble learning) 방법 중 하나입니다.
앙상블 학습은 같은 데이터를 기반으로 학습한 여러 모델을 비교 및 결합하여 개별적인 모델보다 성능이 더 나은 최종 모델을 만드는 것입니다.
부스팅은 앞서 보팅(voting)과 같은 독립접 앙상블 방법과 달리 의존적 앙상블 방법입니다.
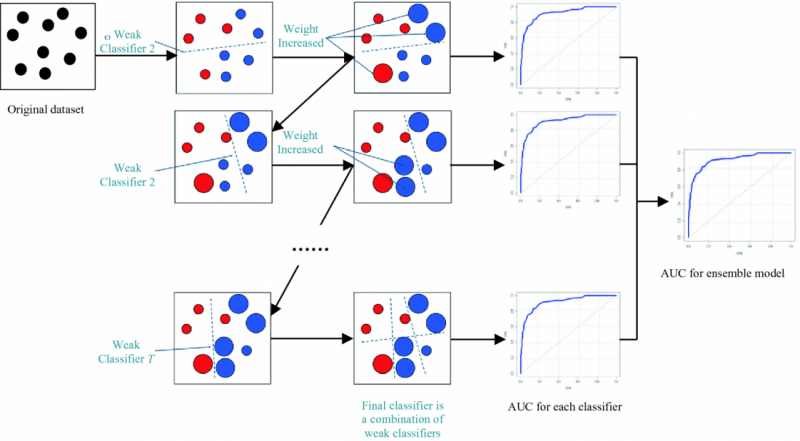
부스팅의 핵심 아이디어는 분류하기 어려운 데이터에 집중한다는 것입니다.
즉, 데이터 포인트에 가중치를 할당함으로써 학습 중 관심의 정도를 반영할 수 있습니다.
학습 초기에는 모든 데이터 포인트에 동일한 가중치를 할당하고, 점차 학습이 진행되면서 올바르게 분류된 데이터 포인트의 가중치는 감소하는 반면에 잘못 분류된 데이터 포인트 가중치는 증가하게 됩니다.
즉, 이전 단계에서 만들어진 학습 모델은 다음 단계에서 사용할 데이터 셋의 가중치를 변경하는 데 사용됩니다.
이것은 이전 모델의 성능에 영향을 받는다는 의미입니다.
단계가 진행되면서 학습에 사용되는 데이터 또한 가중치에 의존하여 추출됩니다.
위와 같은 특징으로 인해 부스팅은 보팅, 배깅과 달리 병렬로 처리되는 것이 아니라 순차적으로 처리됩니다.
실습은 sklearn AdaBoostClassifier를 이용하여 유방암 데이터를 분류해 보겠습니다.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
# 데이터 불러오기
raw_breast_cancer = datasets.load_breast_cancer()
# 피쳐, 타겟 데이터 지정
X = raw_breast_cancer.data
y = raw_breast_cancer.target
# 트레이닝/테스트 데이터 분할
X_tn, X_te, y_tn, y_te=train_test_split(X, y, random_state=0)
# 데이터 표준화
std_scale = StandardScaler()
std_scale.fit(X_tn)
X_tn_std = std_scale.transform(X_tn)
X_te_std = std_scale.transform(X_te)
# 에이다 부스트 학습
clf_ada = AdaBoostClassifier(random_state=0)
clf_ada.fit(X_tn_std, y_tn)
# 예측
pred_ada = clf_ada.predict(X_te_std)
print(pred_ada)
# 정확도
accuracy = accuracy_score(y_te, pred_ada)
print(accuracy)
# confusion matrix 확인
conf_matrix = confusion_matrix(y_te, pred_ada)
print(conf_matrix)
# 분류 레포트 확인
class_report = classification_report(y_te, pred_ada)
print(class_report)'AI > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 차원 축소 (0) | 2023.06.01 |
|---|---|
| [Machine Learning] 스태킹 (Stacking) (1) | 2023.05.31 |
| [Machine Learning] 배깅 (Bootstrap Aggregating, Bagging) (0) | 2023.05.31 |
| [Machine Learning] 보팅 (Voting) (0) | 2023.05.31 |
| [Machine Learning] 서포트 벡터 머신 (Support Vector Machine, SVM) (1) | 2023.05.31 |