딥러닝을 이용한 이미지 분류는 보통 CNNs을 사용합니다. CVPR(Computer Vision and Pattern Recognition)의 최신 연구 동향을 보면 CNNs 보다 Transformers, Radiance Fields, Diffusion 모델 등을 더 많이 사용하고 있으나, CNNs은 컴퓨터 비전의 가장한 중요한 요소이므로 반드시 숙지해야 합니다.
CNNs을 이용한 이미지 분류는 단순히 컨볼루션 레이어를 사용하여 이미지의 feature를 추출하고 출력층을 분류 class 개수로 설정하면 됩니다. CNNs의 내부는 conv, maxpool, dropout, flatten 등을 사용할 수 있으며 conv과 flatten은 필수입니다.

flatten을 사용하는 이유는 이미지의 다차원 데이터를 1차원으로 변환하여 출력층과 연결할 수 있는 FC(Fully Connected Layer)를 만들기 위함입니다.
히든 레이어의 구성은 설계하기 나름이기 때문에, CNNs을 이용한 TensorFlow와 PyTorch의 이미지 분류 튜토리얼을 참조해 주세요.
본 포스팅에서는 몇 가지 Pre-trained 모델들을 이용하여 이미지를 분류해 보겠습니다.
사용할 모델 리스트는 다음과 같습니다.
| Models |
| DenseNet121 |
| DenseNet201 |
| MobileNetV2 |
| MobileNetV3Large |
| EfficientNetB0 |
| EfficientNetB1 |
| InceptionV3 |
| ResNet50 |
| ResNet50V2 |
| ResNet152V2 |
| VGG16 |
| VGG19 |
| Xception |
또한 학습에 사용할 이미지를 /data/train과 /data/test 디렉토리에 나누어 저장합니다. /data/train에는 이미지 class별로 디렉토리를 생성합니다.
이미지 분류 class는 airplane, car, cat, dog, flower, fruit, motorbike, person으로 분류 개수는 총 8개입니다.
이미지는 CIFAR 데이터를 다운로드 받아 사용하시거나, 다른 데이터셋을 사용해도 됩니다.
사용된 py 파일은 util.py, train.py, test.py 3개입니다.
[util.py]
import pandas as pd
from pathlib import Path
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import numpy as np
from time import perf_counter
import os
from sklearn.metrics import accuracy_score
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.inception_resnet_v2 import preprocess_input
def generate_data_frame(data_dir):
dir = Path(data_dir)
filepaths = list(dir.glob(r'**/*.jpg'))
labels = [str(filepaths[i]).split("\\")[-2] \
for i in range(len(filepaths))]
filepath = pd.Series(filepaths, name='Filepath').astype(str)
labels = pd.Series(labels, name='Label')
df = pd.concat([filepath, labels], axis=1)
df = df.sample(frac=1, random_state=0).reset_index(drop=True)
return df
def show_data(df):
fig, axes = plt.subplots(nrows=4, ncols=10, figsize=(15, 7),
subplot_kw={'xticks': [], 'yticks': []})
for i, ax in enumerate(axes.flat):
ax.imshow(plt.imread(df.Filepath[i]))
ax.set_title(df.Label[i], fontsize=12)
plt.tight_layout(pad=0.5)
plt.show()
def show_category(df, col_name):
vc = df[col_name].value_counts()
plt.figure(figsize=(9, 5))
sns.barplot(x=vc.index, y=vc, palette="rocket")
plt.title("Number of pictures of each category", fontsize=15)
plt.show()
def create_gen(train_df, test_df):
train_generator = tf.keras.preprocessing.image.ImageDataGenerator(
preprocessing_function=tf.keras.applications.mobilenet_v2.preprocess_input,
validation_split=0.1
)
test_generator = tf.keras.preprocessing.image.ImageDataGenerator(
preprocessing_function=tf.keras.applications.mobilenet_v2.preprocess_input
)
train_images = train_generator.flow_from_dataframe(
dataframe=train_df,
x_col='Filepath',
y_col='Label',
target_size=(224, 224),
color_mode='rgb',
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=0,
subset='training',
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest"
)
val_images = train_generator.flow_from_dataframe(
dataframe=train_df,
x_col='Filepath',
y_col='Label',
target_size=(224, 224),
color_mode='rgb',
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=0,
subset='validation',
rotation_range=30,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest"
)
test_images = test_generator.flow_from_dataframe(
dataframe=test_df,
x_col='Filepath',
y_col='Label',
target_size=(224, 224),
color_mode='rgb',
class_mode='categorical',
batch_size=32,
shuffle=False
)
return train_generator, test_generator, train_images, val_images, test_images
def get_model(model):
kwargs = {'input_shape': (224, 224, 3),
'include_top': False,
'weights': 'imagenet',
'pooling': 'avg'}
pretrained_model = model(**kwargs)
pretrained_model.trainable = False
inputs = pretrained_model.input
x = tf.keras.layers.Dense(128, activation='relu')(pretrained_model.output)
x = tf.keras.layers.Dense(128, activation='relu')(x)
outputs = tf.keras.layers.Dense(8, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
return model
def get_results_of_models(models, train_images, val_images, test_images, test_label):
for name, model in models.items():
m = get_model(model['model'])
models[name]['model'] = m
start = perf_counter()
history = m.fit(train_images, validation_data=val_images, epochs=1, verbose=0)
duration = perf_counter() - start
duration = round(duration, 2)
models[name]['perf'] = duration
print(f'** {name:20} trained in {duration} sec **')
val_acc = history.history['val_accuracy']
models[name]['val_acc'] = [round(v, 4) for v in val_acc]
print()
for name, model in models.items():
pred = models[name]['model'].predict(test_images)
pred = np.argmax(pred, axis=1)
labels = (train_images.class_indices)
labels = dict((v, k) for k, v in labels.items())
pred = [labels[k] for k in pred]
y_test = list(test_label)
acc = accuracy_score(y_test, pred)
models[name]['acc'] = round(acc, 4)
print(f'** {name} has a {acc * 100:.2f}% accuracy on the test set **')
print()
# Create a DataFrame with the results
models_result = []
for name, v in models.items():
models_result.append([name, models[name]['val_acc'][-1],
models[name]['acc'],
models[name]['perf']])
results_df = pd.DataFrame(models_result,
columns=['model', 'val_accuracy', 'accuracy', 'Training time (sec)'])
results_df.sort_values(by=['val_accuracy', 'accuracy', 'Training time (sec)'], ascending=[False, False, True], inplace=True)
results_df.reset_index(inplace=True, drop=True)
return results_df
def show_dataframe(df, x, y, title):
plt.figure(figsize=(15, 8))
sns.barplot(x=x, y=y, data=df)
plt.title(title, fontsize=15)
# plt.ylim(0,1)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
def load_data(images_dir, start=0, end=10000):
IMAGE_SIZE = (224, 224)
name_list = []
img_list = []
files = os.listdir(images_dir)
cnt = 0
for file in files[start:end]:
try:
path = images_dir + '/' + file
img = image.load_img(path, target_size=IMAGE_SIZE)
img = image.img_to_array(img)
name_list.append(file)
img_list.append(img)
cnt += 1
print(cnt, 'path: %s \t shape: %s' % (path, str(img.shape)))
del img, file
except FileNotFoundError as e:
print('ERROR : ', e)
names = np.array(name_list)
imgs = np.stack(img_list)
imgs = preprocess_input(imgs)
return names, imgs
[train.py]
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import numpy as np
import tensorflow as tf
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pickle
import pandas as pd
import click
from util import generate_data_frame, show_data, show_category, show_dataframe, \
create_gen, get_results_of_models
@click.command()
@click.option('--data_dir', default='data/train', help='Data path')
@click.option('--batch_size', default=32, help='Batch size')
@click.option('--epochs', default=10, help='Epochs')
def run(data_dir, batch_size, epochs):
df = generate_data_frame(data_dir)
print(df.head(5))
print(f'Number of pictures: {df.shape[0]}')
print(f'Number of different labels: {len(df.Label.unique())}')
print(f'Labels: {df.Label.unique()}')
print('Label Counts')
print(df.Label.value_counts())
# show_data(df)
# show_category(df, 'Label')
train_df, test_df = train_test_split(df, test_size=0.1, random_state=0)
print(train_df.shape, test_df.shape)
train_generator, test_generator, train_images, val_images, test_images = create_gen(train_df, test_df)
# Pre-trained models
models = {
"DenseNet121": {"model": tf.keras.applications.DenseNet121, "perf": 0},
"MobileNetV2": {"model": tf.keras.applications.MobileNetV2, "perf": 0},
"DenseNet201": {"model": tf.keras.applications.DenseNet201, "perf": 0},
"EfficientNetB0": {"model": tf.keras.applications.EfficientNetB0, "perf": 0},
"EfficientNetB1": {"model": tf.keras.applications.EfficientNetB1, "perf": 0},
"InceptionV3": {"model": tf.keras.applications.InceptionV3, "perf": 0},
"MobileNetV3Large": {"model": tf.keras.applications.MobileNetV3Large, "perf": 0},
"ResNet152V2": {"model": tf.keras.applications.ResNet152V2, "perf": 0},
"ResNet50": {"model": tf.keras.applications.ResNet50, "perf": 0},
"ResNet50V2": {"model": tf.keras.applications.ResNet50V2, "perf": 0},
"VGG19": {"model": tf.keras.applications.VGG19, "perf": 0},
"VGG16": {"model": tf.keras.applications.VGG16, "perf": 0},
"Xception": {"model": tf.keras.applications.Xception, "perf": 0}
}
results_df = get_results_of_models(models, train_images, val_images, test_images, test_df.Label)
print()
print('========== Results of models ==========')
print(results_df)
results_df.to_csv('models.csv', index=False)
show_dataframe(results_df, 'model', 'accuracy', 'Accuracy on the test set')
show_dataframe(results_df, 'model', 'Training time (sec)', 'Training time for each model in sec')
# Get best pre-trained model
best_model_name = results_df['model'][0]
model = models[best_model_name]['model']
# Train best pre-trained model (epcohs 1 -> 10)
history = model.fit(train_images, validation_data=val_images, batch_size=batch_size, epochs=epochs)
pd.DataFrame(history.history)[['accuracy', 'val_accuracy']].plot()
plt.title("Accuracy")
plt.show()
pd.DataFrame(history.history)[['loss', 'val_loss']].plot()
plt.title("Loss")
plt.show()
# Save model
model.save(best_model_name + '.h5')
# Predict the label of the test_images
pred = model.predict(test_images)
pred = np.argmax(pred, axis=1)
# Map the label
labels = (train_images.class_indices)
labels = dict((v, k) for k, v in labels.items())
with open('labels.pkl', 'wb') as f:
pickle.dump(labels, f)
pred = [labels[k] for k in pred]
y_test = list(test_df.Label)
# Show Classification Report
class_report = classification_report(y_test, pred, zero_division=1)
print()
print('========== Classification Report of Best Model (%s) ==========' % best_model_name)
print(class_report)
cf_matrix = confusion_matrix(y_test, pred, normalize='true')
plt.figure(figsize=(10, 7))
sns.heatmap(cf_matrix, annot=False, xticklabels=sorted(set(y_test)), yticklabels=sorted(set(y_test)), cbar=False)
plt.title('Normalized Confusion Matrix', fontsize=23)
plt.xticks(fontsize=15, rotation=45)
plt.yticks(fontsize=15, rotation=45)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
run()
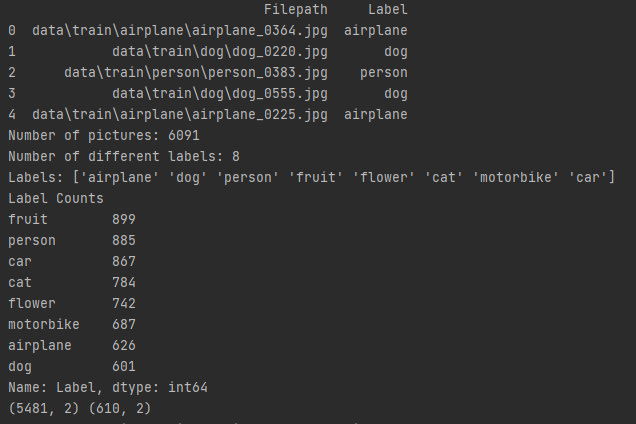
먼저, train.py의 run() 함수에서 이미지 개수, class 개수, class 항목, class 별 이미지 개수, 학습 및 검증 데이터의 shape를 확인합니다.
그리고 util.create_gen() 함수를 통해 데이터 제너레이터와 학습, 검증 테스트 데이터를 생성합니다.
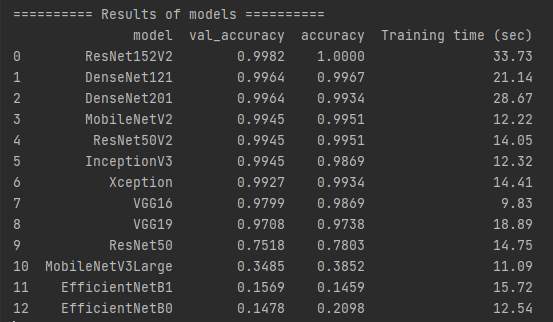
다음으로, util.get_results_of_models() 함수를 통해 각 Pre-trained 모델들의 성능을 평가합니다. 여기서 Epochs은 1로 설정하였습니다.
현재 사용한 데이터셋을 기반으로 ResNet152V2 모델이 가장 좋은 성능을 보였습니다.
모델의 성능 순서 기준은 val_accuracy, accuracy, Training time입니다.
다음으로, 가장 성능이 좋은 ResNet152V2 모델을 Epochs 10으로 설정하여 다시 학습합니다.
학습된 최종 모델 ResNet152V2의 classification report는 다음과 같습니다.
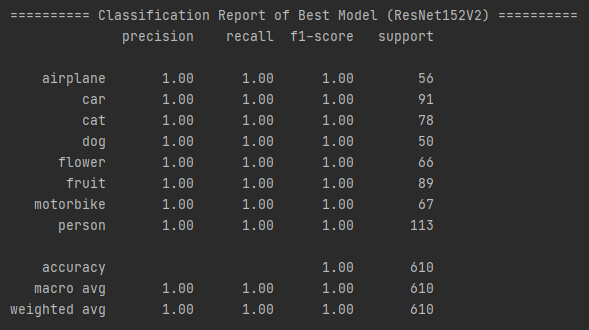
정확도는 100%입니다.
경험상, class 개수를 50개 이상으로 하더라도 Pre-trained 모델을 사용한 이미지 분류의 성능은 거의 100%에 가깝게 나온것을 확인했습니다.
다음으로 테스트 데이터를 모델의 입력으로 사용하여 결과를 확인해 보겠습니다.
[test.py]
import click
import numpy as np
import pandas as pd
import pickle
from tensorflow.python.keras.saving.save import load_model
from util import load_data
@click.command()
@click.option('--data_dir', default='data/test', help='Data path')
@click.option('--model_name', default='ResNet152V2', help='Model name')
def run(data_dir, model_name):
img_names, X_test = load_data(data_dir)
loaded_model = load_model(model_name + '.h5')
pred = loaded_model.predict(X_test)
pred = np.argmax(pred, axis=1)
with open('labels.pkl', 'rb') as f:
labels = pickle.load(f)
pred = [labels[k] for k in pred]
results_df = pd.DataFrame({'image_name': img_names, 'class': pred})
results_df.to_csv('results.csv', index=False)
if __name__ == '__main__':
run()
결과는 csv 파일로 확인할 수 있습니다.
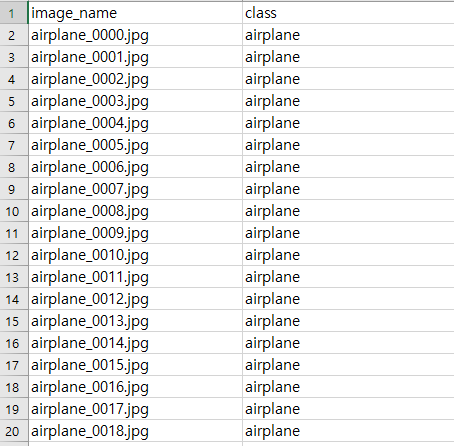
results.csv를 확인해 보면, image_name과 class로 구성되어 있습니다.
테스트 이미지 개수가 많아 결과의 일부만 업로드하였으나, 모든 이미지를 정확하게 예측한 결과를 확인할 수 있었습니다.
Pre-trained 모델 사용 방법을 숙지하면, 본 포스팅처럼 파인튜닝(Fine-tuning)을 통해 다른 컴퓨터 비전 Task에도 유용하게 사용할 수 있습니다.
'AI > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 시맨틱 분할 (Semantic Segmentation) (0) | 2023.06.25 |
|---|---|
| [Computer Vision] 객체 탐지 (Object Detection) (0) | 2023.06.19 |
| [Computer Vision] 이미지 검색 (0) | 2023.06.16 |