
Paper: http://ai.stanford.edu/~ang/papers/icml11-MultimodalDeepLearning.pdf
Abstract
- Deep networks는 single modalities에 대해서 featrue learning을 잘 수행하고 있다.
- 만일 multiple modalities 학습이 가능한 상황이라면, single modality보다 더 좋은 결과를 얻을 수 있다.
- 본 논문에서는 multiple modalities를 학습하는 deep networks를 제안한다.
Modalities 간의 representation 학습 방법
Introduction
- 인간은 시각, 미각, 촉각, 언어 등 다양한 감각을 통합하여 무엇인가를 인식한다.
인간은 시청각 정보를 통합하여 음성을 인식한다. (McGurk effect)- Multimodal 학습은 multiple modalities로부터 관련 feature를 찾는 것이 중요하다.
예를 들어,
음성 인식을 위한 오디오 및 시각적 데이터는 음소나 입술 자세(또는 동작)와 같은 "중간 레벨"의 상관 관계를 갖는다.- 본 논문에서는 Feature Learning, Supervised Training, Testing 세 단계로 나눠 multimodal 학습을 진행한다.

Background
- 손으로 쓴 숫자와 문자에 대한 유용한 representation을 생성하기 위한 연구가 있다.(Hinton & Salakhutdinov, 2006; Salakhutdinov & Hinton, 2009)
핵심 아이디어는 RBM(Restricted Boltzmann Machines)을 fine-tuning 하는 것이다.
RBM은 데이터의 확률 분포를 학습하는 비지도 학습 모델이며, 입력층과 은닉층으로 2개로 구성된다.


- 본 논문에서는 RBM을 기반으로 Multimodal 학습을 진행한다.
Learning architectures
- 학습 모델은 audio-visual bimodal 형태이며, 연속적인 audio와 visual을 입력으로 사용한다.
- (Figure 2a, b)의 hidden variables는 sigmoid를 사용해 입력에 대한 새로운 representation으로 정의한다.
- (Figure 2a, b)를 multimodal model과 비교를 위한 baseline으로 사용한다.
- Multimodal model을 학습하기 위해 (Figure 2c) 처럼 audio와 video data를 concatenate한다.
- audio와 video data의 correlations은 non-linear이기 때문에 RBM으로 multimodal representation을 학습하기 어렵다.
- 따라서 각 modality에 deep learning layers를 적용한다.
- 첫 번째 hidden variables에 sigmoid를 사용하여 representation을 생성함으로써 모델이 modality 전반에 걸쳐 correlations을 더 쉽게 학습할 수 있다.

- 그러나 위 mulimodal model들은 여전히 문제가 있다.
첫째, 모델이 modalities 전반에 걸쳐 상관 관계를 발견하려는 명시적인 목표가 없다.
둘째, single modality 학습만 가능하다면 모델을 사용하기가 어렵다.- 따라서 두 가지 문제를 모두 해결하는 deep autoencoder를 제안한다.
(Figure 3a)는 video data만 입력으로 사용했을 때, video와 audio representation을 reconstruct한다.
그러나 확장성이 좋지 않다.(Figure 3b)는 학습데이터 중 audio 1/3, video 1/3, audio와 video를 포함하여 1/3 모두를 입력으로 사용한다.
이러한 방법은 존재하지 않는 입력 modality에 robust한 모델 학습에 효과적이다.
Experiments and Results
- Data Preprocessing
audio data는 PCA를 통해 483차원의 벡터로 변환하고, 연속적인 10개의 프레임을 입력으로 사용한다.
video data는 ROI(region-of-interest)만 추출하기 위해 60x80픽셀로 자른 후
PCA를 통해 32차원의 벡터로 변환하고, 연속적인 4개 프레임을 입력으로 사용한다.- Datasets
CUAVE (Patterson et al., 2002)
AVLetters (Matthews et al., 2002)
AAVLetters2 (Cox et al., 2008)
TIMIT (Fisher et al., 1986)
Stanford Dataset- Cross Modality Learing
multiple modalities가 주어졌을 때, one modality에 대해 representation을 잘 학습할 수 있는지 평가한다.

- Multimodal Fusion Results
Audio features에 video featrue를 concatenate하면 성능이 저하될 수 있는 경우가 많다.
(Gurban & Thiran, 2009; Papandreou et al., 2007; Pitsikalis et al., 2006; Papandreou et al., 2009)
따라서 clean audio와 noisy audio 상황 모두에서 모델을 평가한다.
- Shared Representation Learning
audio data와 video data를 통해 shared representation을 잘 학습할 수 있는지 평가한다.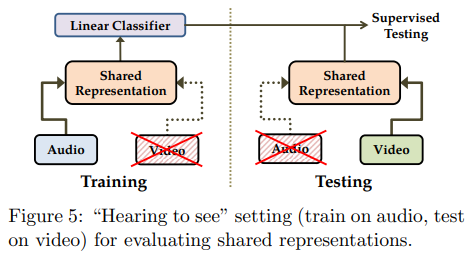

Discussion
- Feature engineering은 시간이 많이 소요되고 어렵다.
- 이러한 어려움은 multiple modalities에서 더욱 어려워진다.
- 본 논문에서는 이러한 어려움에 deep learning을 적용할 수 있는 방법을 제안하였다.