모델의 성능을 평가하는 방법에는 여러 가지가 있습니다.
먼저 이진 분류 케이스는 아래 표와 같습니다.

정답으로 분류되는 경우(모델이 정답을 맞힌경우)는 데이터를 양성(Positive)으로 예측했을 때, 실젯값도 양성일 때는 정답(True)으로 분류하고, 이 경우를 True Positive(TP)라고 합니다.
반대로 음성(Negative)으로 예측했을 때, 실젯값도 음성일 때는 True Negative(TN)라고 합니다.
오답으로 분류되는 경우는 양성으로 예측했을 때, 실젯값은 음성인 경우 False Positive(FP)라고 합니다.
그리고 음성으로 예측했을 때, 실젯값은 양성인 경우 False Negative(FN)라고 합니다.
정리하면
모델 예측이 양성이면 Positive, 음성이면 Negative이고
그것이 실젯값과 일치(모델:Positive, 실제:Positive 또는 모델:Negative, 실제:Negative)하면 True,
실젯값과 불일치(모델:Positive, 실제:False 또는 모델:False, 실제:Positive)하면 False입니다.
사이킷런의 confusion_matrix()를 사용하면 예측값과 실젯값의 빈도를 행렬로 확인할 수 있습니다.
여기서 행은 실젯값을 의미하고 열은 예측값을 의미합니다.
다시 말해, 대각 원소는 예측값과 실젯값이 일치하는 경우를 의미하고 대각 원소가 아닌 원소는 예측값과 실젯값의 차이를 의미합니다.
from sklearn.metrics import confusion_matrix
y_pred = [1, 1, 3, 2]
y_true = [0, 1, 2, 3]
print(confusion_matrix(y_true, y_pred))
# [[0 1 0 0]
# [0 1 0 0]
# [0 0 0 1]
# [0 0 1 0]]
다음은 이진 분류가 아닌 클래스 3개를 분류하는 케이스입니다.

위 분류표를 기반으로 다양한 성능 평가 기준을 만들 수 있습니다.
1. 정밀도(Precision)
정밀도는 모델이 양성으로 예측했을 때, 실젯값이 양성인 비율입니다.

2. 민감도(Sensitivity), 리콜(Recall), True Positive Rate(TPR)
리콜, 민감도, TPR는 실젯값이 양성인 데이터를 모델이 양성으로 예측하는 비율입니다.

3. 특이도(Specificity)
특이도는 실젯값이 음성인 데이터를 모델이 음성으로 예측하는 비율입니다.

4. False Positive Rate(FPR)
FPR은 실젯값이 음성인 데이터를 모델이 양성으로 예측하는 비율입니다.

5. 정확도(Accuracy)
정확도는 전체 데이터 중 정답으로 분류되는 비율입니다.
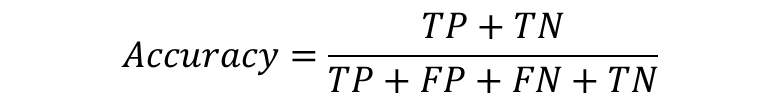
6. ROC 커브(Receiver Operating Characteristic)
ROC 커브는 x축을 FPR로 놓고, y축의 민감도(혹은 TPR) 값을 비교하는 방법입니다.

위 그림에서는 초록색의 경우(Excellent)가 가장 좋은 모델이라고 볼 수 있습니다.
'AI > Machine Learning' 카테고리의 다른 글
| [Machine Learning] K-최근접 이웃 알고리즘 (KNN) (0) | 2022.09.28 |
|---|---|
| [Machine Learning] 모델 성능 평가 - 분류, 회귀 (0) | 2022.09.27 |
| [Machine Learning] 손실 함수 - 비용 함수, 목적 함수 (0) | 2022.09.27 |
| [Machine Learning] 그리드 서치 (0) | 2022.09.13 |
| [Machine Learning] 파이프라인 (0) | 2022.09.13 |