머신러닝에 사용되는 raw 데이터는 대부분 가공되어 있지 않습니다.
데이터 전처리(feature engineering)는 효율적인 학습을 위해 반드시 필요한 작업입니다.
데이터 전처리 방법은 여러가지가 있지만 기본적인 결측치 처리, 데이터 라벨링, 데이터 스케일링을 소개합니다.
1. 결측치 처리
데이터 셋에서 일부 데이터의 값이 존재하지 않는 경우 이를 결측치라고 합니다.
결측치는 학습에 문제가 될 수 있기 때문에 결측치 처리(변경 또는 삭제)는 중요한 작업입니다.
import numpy as np
import pandas as pd
df = pd.DataFrame([
[42, 'male', 12, 'reading', 'class2'],
[35, 'unknown', 3, 'cooking', 'class1'],
[300, 'female', 7, 'cycling', 'class3'],
[300, 'unknown', 45, 'unknown', 'unknown']
])
df.columns = ['age',
'gender',
'month_birth',
'hobby',
'target']
print(df)
위와 같이 DataFrame을 구성한다면, 모든 데이터가 존재하나 부적절한 값들이 존재합니다.
예를 들어 'age'에서 300이라는 값은 인간의 수명을 고려했을 때, 부적절하다고 볼 수 있습니다.
'month_birth'에서 45라는 값도 부적절하며, 나머지 feature에서 'unknown'이라는 값도 마찬가지입니다.
따라서 이러한 값들을 결측치로 변경해보겠습니다.
print('df["age"].unique():', df['age'].unique())
print('df["gender"].unique():', df['gender'].unique())
print('df["month_birth"].unique():', df['month_birth'].unique())
print('df["hobby"].unique():', df['hobby'].unique())
print('df["target"].unique():', df['target'].unique())결측치 변경을 위해 먼저 칼럼에 어떤 값이 존재하는지 파악해야 합니다.
unique()를 통해 어떤 값으로 이루어져 있는지 확인합니다.
'age'의 경우 42, 35, 300의 값으로 이루어져 있다는 것을 알 수 있습니다.
따라서 부적절한 값을 결측치로 변경합니다.
df.loc[df['age'] > 100, ['age']] = np.nan
df.loc[df['gender'] == 'unknown', ['gender']] = np.nan
df.loc[df['month_birth'] > 12, ['month_birth']] = np.nan
df.loc[df['hobby'] == 'unknown', ['hobby']] = np.nan
df.loc[df['target'] == 'unknown', ['target']] = np.nan
print(df)데이터 셋에서 각 칼럼의 결측치 개수는 df.isnull().sum()을 통해 확인할 수 있습니다.
print(df.isnull().sum())결측치를 확인하고, 먼저 결측치를 포함한 데이터를 삭제하는 방법입니다.
결측치를 포함한 행을 삭제할 경우 1, 2, 3 행의 데이터가 삭제됐습니다.
df2 = df.dropna(axis=0)
print(df2)결측치를 포함한 열을 삭제할 경우 모든 데이터가 삭제됐습니다.
df3 = df.dropna(axis=1)
print(df3)모든 값이 결측치인 행을 삭제할 경우 3행의 데이터가 삭제됐습니다. axis는 default가 0이기 때문에 행이 삭제됩니다.
df4 = df.dropna(how='all')
print(df4)결측치를 제외한 값이 n개 미만인 행을 삭제할 경우 (n=2) 위와 같이 3행의 데이터가 삭제됐습니다.
df5 = df.dropna(thresh=2)
print(df5)특정 칼럼에 결측치가 있는 행을 삭제할 경우 (column='gender') 1, 3행의 데이터가 삭제됐습니다.
df6 = df.dropna(subset=['gender'])
print(df6)
결측치 삭제 대신 변경하는 방법은 다음과 같습니다.
df.fillna()를 통해 결측치를 다른 값으로 변경할 수 있습니다.
아래 코드는 특정값으로 변경했으나, 결측치에 평균값 등을 계산하여 대체할 수도 있습니다.
alter_values = {'age': 0,
'gender': 'U',
'month_birth': 0,
'hobby': 'U',
'target': 'class4'}
df7 = df.fillna(value=alter_values)
print(df7)2. 클래스 라벨링
라벨링은 입력 데이터의 features가 무엇을 나타내는지 이름표를 붙이는 작업이라고 볼 수 있습니다.
위 데이터 셋을 보면 4개의 데이터가 존재하고 순서대로 타겟은 class2, class1, class3, class4입니다.
즉, 데이터 featrues(age, gender, month_birth, hobby)를 입력으로 하여 출력을 네 가지로 분류한다는 이야기입니다.
머신러닝에서 출력은 (입력도 마찬가지) 문자열 형태가 아니라 정수형이나 실수형으로 변경해줘야 합니다.
class1 -> 0, class2 -> 1, class3 -> 2, class4 -> 3 으로 변경해 보겠습니다.
from sklearn.preprocessing import LabelEncoder
df8 = df7
class_label = LabelEncoder()
data_value = df8['target'].values
y_new = class_label.fit_transform(data_value)
print(y_new) # [1 0 2 3]이제 클래스 라벨링한 'target'을 기존 데이터셋에 반영합니다.
df8['target'] = y_new
print(df8)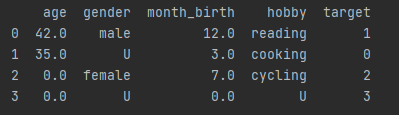
3. 원-핫 인코딩
원-핫 인코딩(one-hot encoding)은 클래스 라벨링의 또 다른 방법입니다. 이전에는 0, 1, 2, ... n으로 라벨링 했지만 0과 1만을 이용해 벡터로 변환하는 것입니다. 결과는 4개의 차원으로 이루어진 벡터입니다.
df9 = df8
df10 = pd.get_dummies(df9['target'])
print(df10)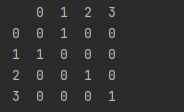
4. 데이터 스케일링
features는 다른 단위를 가지고 있습니다. 위 데이터 셋에서 보더라도 age와 month_birth가 다른 것을 확인할 수 있습니다.
이러한 데이터는 학습에 영향을 줄 수 있기 때문에 (값이 클수록 중요한 feature로 계산될 수 있음) 데이터 값이 단위에 영향을 받지 않도록 변형하는 데이터 스케일링 작업이 필요합니다.
보통 데이터 스케일링을 위해 평균, 분산, 최댓값, 최솟값 등을 구합니다.
(1) 표준화 스케일링
표준화 스케일링 (standard scaling)은 데이터가 평균 0, 표준 편차 1이 되도록 변환하는 방법입니다.
'month_birth' 칼럼의 데이터를 표준화 스케일링 해보겠습니다.
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
x_std = std.fit_transform(df8[['month_birth']])
print(x_std)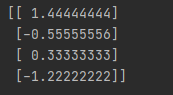
그리고 표준화 스케일링된 데이터의 평균이 0, 표준 편차가 1인지 확인해봅니다.
print(np.mean(x_std)) # 0.0
print(np.std(x_std)) # 1.0(2) 최소-최대 스케일링
최소-최대 스케일링 (min-max scaling) 방법은 데이터 값의 최댓값을 1, 최솟값을 0으로 만드는 방법입니다.
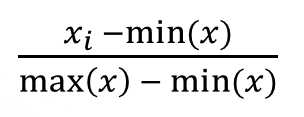
최소-최대 스케일링으로 'month_birth' 칼럼의 데이터 값을 변환해 보겠습니다.
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler()
minmax.fit(df8[['month_birth']])
x_minmax = minmax.transform(df8[['month_birth']])
print(x_minmax)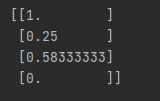
12.0, 3.0, 7.0, 0.0 값이 1.0, 0.25, 0.58333333, 0.0으로 변경되었습니다.
그 외에도 많은 스케일링 방법이 있습니다.
마지막으로 주어진 데이터 셋을 라벨링 + 스케일링 해보겠습니다.
processed_df = df8
# one-hot encoding (gender, hobby)
processed_df = pd.get_dummies(processed_df)
# min-max scaling (age)
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler()
minmax.fit(df8[['age']])
x_minmax = minmax.transform(df8[['age']])
processed_df['age'] = x_minmax
# min-max scaling (month_birth)
minmax = MinMaxScaler()
minmax.fit(df8[['month_birth']])
x_minmax = minmax.transform(df8[['month_birth']])
processed_df['month_birth'] = x_minmax
# one-hot encoding (target)
from sklearn.preprocessing import OneHotEncoder
hot_encoder = OneHotEncoder()
y = df7[['target']]
y_hot = hot_encoder.fit_transform(y)
processed_df['target'] = y_hot.toarray().tolist()
# print keys
print(processed_df.keys())
# rearrange colums
processed_df = processed_df[['age', 'month_birth', 'gender_U', 'gender_female',
'gender_male', 'hobby_U', 'hobby_cooking', 'hobby_cycling', 'hobby_reading','target']]
# save DataFrame
processed_df.to_csv("processed_df.csv", index=False)
'AI > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 선형대수 - 특이값 분해 (0) | 2022.08.09 |
|---|---|
| [Machine Learning] 선형대수 - 고윳값 분해 (0) | 2022.08.09 |
| [Machine Learning] Sklearn을 이용한 머신러닝 데이터 불러오기 (0) | 2022.07.08 |
| [Machine Learning] 머신 러닝이란 (0) | 2021.04.02 |
| [Machine Learning] matplotlib.pyplot를 이용한 데이터 시각화 (0) | 2021.03.09 |