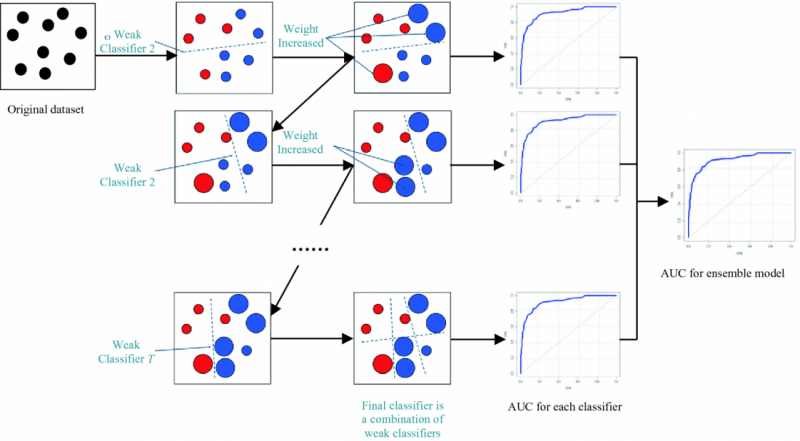
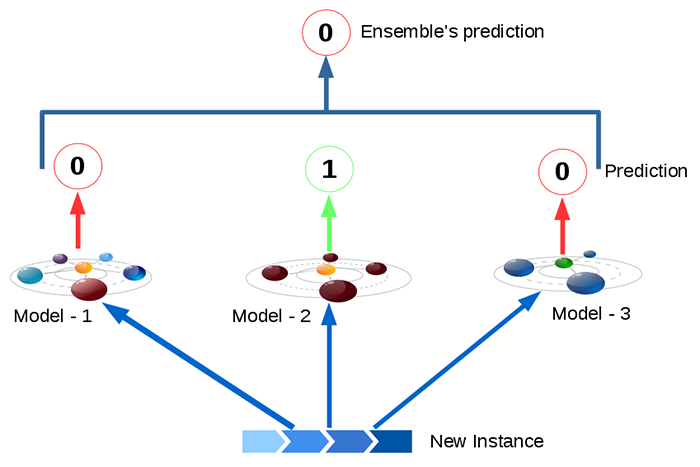
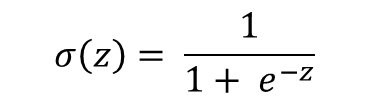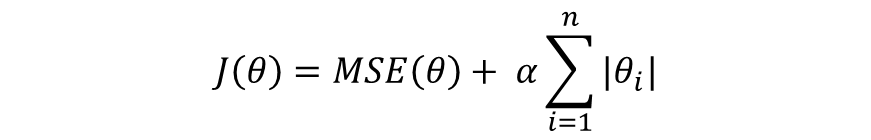부스팅(boosting)은 앙상블 학습(ensemble learning) 방법 중 하나입니다. 앙상블 학습은 같은 데이터를 기반으로 학습한 여러 모델을 비교 및 결합하여 개별적인 모델보다 성능이 더 나은 최종 모델을 만드는 것입니다. 부스팅은 앞서 보팅(voting)과 같은 독립접 앙상블 방법과 달리 의존적 앙상블 방법입니다. 부스팅의 핵심 아이디어는 분류하기 어려운 데이터에 집중한다는 것입니다. 즉, 데이터 포인트에 가중치를 할당함으로써 학습 중 관심의 정도를 반영할 수 있습니다. 학습 초기에는 모든 데이터 포인트에 동일한 가중치를 할당하고, 점차 학습이 진행되면서 올바르게 분류된 데이터 포인트의 가중치는 감소하는 반면에 잘못 분류된 데이터 포인트 가중치는 증가하게 됩니다. 즉, 이전 단계에서 만들어진..